Читатели «Твиттера»: F1 и AWS объединились, чтобы ответить на вопрос — сколько мы можем злить собственное сообщество?
Сегодня менеджмент «Формулы 1», судя по тексту, не без гордости за проделанную работу, опубликовал рейтинг «Самых быстрых пилотов». «F1 и Amazon Machine Learning Solutions Lab целый год потратили на создание алгоритма, что привело к появлению списка самых быстрых пилотов F1. Для этого использовалась последняя версия F1 Insight на базе AWS , которая применяет машинное обучение для сравнения квалификационных показателей гонщиков с течением времени с результатами их товарищей по команде, чтобы установить высший рейтинг. Это означает, что у пилота из хвоста пелетона есть такие же шансы показать себя хорошо, как у пилота, который боролся за поул», — говорится в тексте, опубликованном на официальном сайте F1.
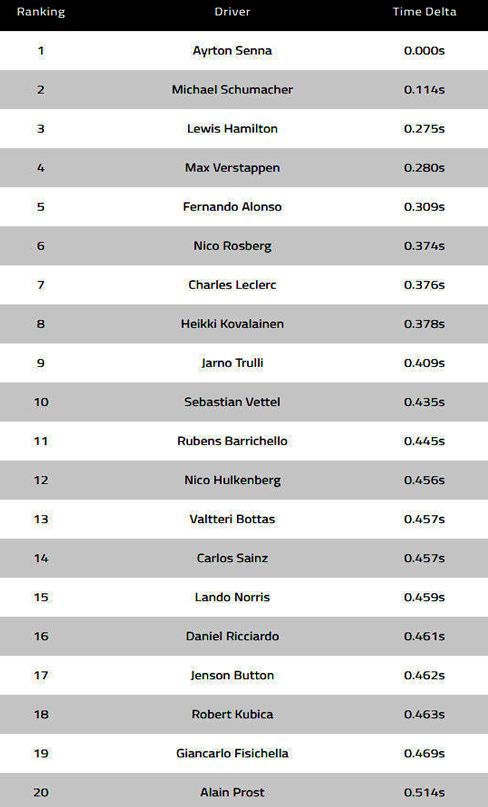
То есть, FOM сразу признает, что только с помощью хитрых вычислений в виртуальном пространстве гонщик конца пелетона имеет равные шансы с обладателем поула. Вычисления, может быть и верные, но посыл явно провальный. Описание исследования можно почитать на сайте F1. Общественность почитала и очень удивилась. Достаточно обратить внимание на тех, кто не попал в список и, собственно, на места в этом списке. Валттери Боттас быстрее Алена Проста? Серьезно? Создается впечатление, что критерии, которые поставили программе для исследования, были составлены, как минимум «криво», а как максимум – бестолково людьми, проработавшими в F1 не один год.
Читатели «Твиттера» F1 не поскупились на едкие выражения в адрес этого исследования. Общий вывод из которых – не стоило затевать составление этого «рейтинга» и уж точно не стоило его публиковать.
@BenHockingF1: F1 и AWS объединились, чтобы использовать машинное обучение, чтобы ответить на извечный вопрос — сколько мы можем злить собственное сообщество?
@rhysR6S: Это просто неуважительно
@reno_je_zlato: Список бессмысленный, хотя начало несколько реалистично. Нельзя сравнивать действующих и бывших гонщиков, потому что это не одно и то же — провести два хороших сезона или 15 лет подряд, поэтому теперь оказывается, что Сайнс лучше Проста, Хаккинена, Менсела, Лауды … F1 — это не просто сравнение данных!
@okeefe_92: Дело в том, что если бы это не был официальный проект Формулы-1, было бы более понятно, но и тогда бы он все еще оставался чертовски хреновым. Но это было AWS, которые имеют достаточно плохую репутацию, как она есть.
И дальше примерно в том же духе. Подавляющее большинство «твитов» имеют негативную оценку. Объяснения, которые дает пресс-служба F1 в своей публикации в целом как раз говорят о том, что задача системе была, скорее всего, поставлена неверно. Отсюда и результат.
«Программное обеспечение AWS для машинного обучения просматривало результаты каждой квалификации с 1983 года и сравнивало выступления напарников по команде, исключая случайные факторы. Для получения показательных данных требовалось соблюдать несколько правил. Напарники должны были провести не менее пяти совместных квалификаций. Также учитывался возраст и возвращение гонщиков после паузы в карьере. Алгоритм также давал более высокий рейтинг гонщикам, доминировавшим над напарниками на протяжении долгого времени и проявившим себя на фоне сильных напарников».
По поводу попадания Хейкки Ковалайнена: «Хотя Ковалайнен и выиграл всего один поул и одну гонку за два года выступлений за McLaren и не добился успехов с Lotus и Caterham в конце карьеры, он очень быстр. В рейтинг самых быстрых гонщиков он попал благодаря своей высокой скорости на одном быстром круге на фоне напарников Льюиса Хэмилтона и Ярно Трулли, занявшего впечатляющее девятое место».
Одним из инициаторов «рейтинга» стал небезызвестный экс-инженер Ferrari, а ныне директор по информационным системам F1 Роб Смедли. Он говорит, что подобный софт используется командами для подбора гонщиков. И далее становится понятно, почему вышли такие результаты.
Роб Смедли: «Что мы должны сделать, как разработчики математических моделей, так это посмотреть, какие данные доступны, а затем убедиться, что мы можем нормализовать эти данные по годам. Модель достаточно умна, чтобы согласовать все остальное, просто понимая, каково время круга. Таким образом, может показаться, что вам понадобится масса данных и … масса данных об автомобилях и все остальное, но вы этого не сделаете. Просто используется время круга, и … у нас есть надежные данные о времени круга за этот период». И хотя рейтинг может показаться забавным, добавляя масла в огонь вековых дебатов, по словам Смедли, сложное моделирование данных похоже на те, которые используются командами F1, когда дело доходит до выбора гонщиков, — пишет сайт F1.
То есть, выходит, был некий доступный набор полных данных – время на круге, а «умная» модель все остальное «согласовала». И из этого были сделаны выводы. Это кажется абсолютной нелепостью.
Редакция E.A.N.